반응형
Transformer 모델은2017년 구글 연구자에 의해 ‘Attention Is All You Need’ 라는 논문에서 처음 소개
주로 자연어 처리(NLP) 분야에서 사용되며, 이후 다양한 분야에서도 활용되고 있음
Transformer의 핵심 아이디어는 전통적인 RNN이나 LSTM과 같이 시퀀스 데이터를 순차적으로 처리하는 대신, 어텐션 메커니즘을 통해 데이터의 전체 시퀀스를 한번에 처리하는 것
이로 인해 모델이 시퀀스 내에서의 장거리 의존성을 더 잘 파악할 수 있게 됨.
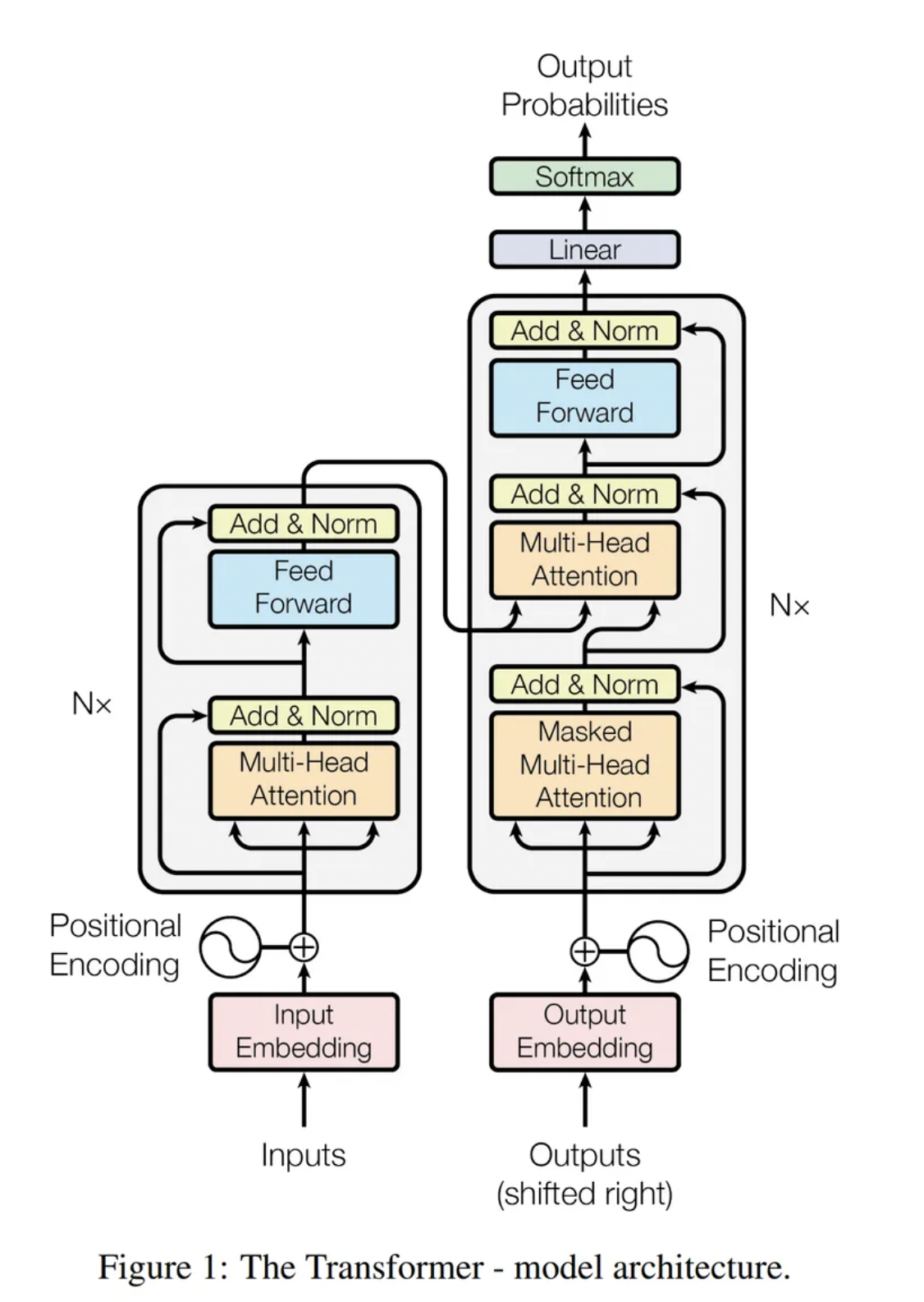
<Transformer의 핵심 구성 요소>
1. 어텐션 메커니즘(Attention Mechanism):
- Transformer 의 핵심은 어텐션 메커니즘으로, 입력 시퀀스의 모든 단어 사이의 관계를 동시에 계산. 이를 통해 모델이 중요한 정보에 집중하고, 덜 중요한 정보는 무시할 수 있음.
- 어텐션은 크게 세 가지 주요 구성 요소로 나눌 수 있음: 쿼리(Query), 키(Key), 밸류(Value),
- ’Scaled Dot-Product Attention’과 ‘Multi-Head Attention’이 이 개념을 확장함
2. 멀티 헤드 어텐션(Muti-Head Attention):
- Transformer는 멀티 헤드 어텐션을 사용하여 다양한 위치에서 정보를 동시에 집중할 수 있음. 이는 같은 정보를 다른 시점에서 다른 관점으로 바라보는 것을 가능하게 하여, 모델이 다양한 특성을 더 잘 학습할 수 있도록 함.
3. 포지션 인코딩(Positional Encoding):
- Transformer는 순차적인 정보를 처리하지 않기 때문에, 시퀀스 내에서 단어의 위치 정보를 모델에 제공하기 위해 포지셔널 인코딩을 사용함.
- 각 단어에 고유한 위치 정보를 추가함으로써, 모델이 단어의 순서를 인식할 수 있게 해줌
4. 인코더와 디코더(Encoder & Decoder):
- Transformer 모델은 인코더와 디코더의 스택으로 구성
- 인코더는 입력 시퀀스를 처리하여 중간 표현을 생성하고, 디코더는 중간표현을 사용하여 출력 시퀀스를 생성함
- 각 인코더와 디코더는 멀티 헤드 어텐션과 포지셔널 인코딩, 그리고 피드포워드 신경망으로 구성됨
<Transformer 장점>
- 병렬처리: Transformer 는 시퀀스 내 모든 단어를 동시에 처리할 수 있어, 병렬 처리가 가능하고 학습속도가 매우 빠름
- 장거리 의존성 학습: 어텐션 메커니즘 덕분에, Transformer는 긴 시퀀스 내에서 장거리 의존성을 효과적으로 학습할 수 있음
- 유연성과 범용성: Transformer는 다양한 NLP 작업에 적용이 가능하며, GPT와 BERT와 같은 파생 모델을 통해 텍스트 생성, 문장분류, 질의응답 등 다양한 분야에서 탁월한 성능을 보여줌
* Transformer 모델은 NLP 분야에서 혁명을 일으켰으며, 현재까지도 연구와 응용에서 중요한 위치를 차지하고 있음.
반응형
'딥러닝' 카테고리의 다른 글
| [논문 리뷰] CRAFT(Character Region Awareness for Text Detection) (0) | 2024.04.11 |
|---|---|
| [딥러닝] CNN 이란? (0) | 2024.04.09 |

