반응형
Weighted Average Ensemble: 가중 평균 앙상블 소개
1) 앙상블의 일부 모델이 다른 모델보다 더 많은 기술을 지니고 있어 더 많은 기여를 한다고 가정
2) 모델 예측값에 고정 가중치가 할당됨
3) 투표 앙상블의 확장: 모든 모델이 동일하게 학습되고, 앙상블에 의해 만들어진 예측에 비례적 기여를 함
4) 기여도 결정 = 기능 또는 기술에 비례하여 가중치가 부여됨
5) 투표 앙상블에서 모델 예측의 평균 = 가중 평균 앙상블에서 모델의 기여도에 비례하여 계산
6) 모든 모델이 동등하게 효과적이라는 투표 앙상블의 한계를 극복
7) 분류: 각 클래스 레이블에 대한 가중치 합을 계산 / / 회귀: 앙상블 구성원의 예측 산술 평균을 계산하는 방식
Weighted Voting Ensemble 소개
1) 정의: 기여도에 따라 각 모델의 예측값에 가중치(weight)를 주어, 최종 예측값을 만드는 앙상블 기법
2) 특징:
- 가중 평균 앙상블과 가중 합계 앙상블 모두 투표 앙상블의 확장형
- 투표 앙상블 경우, 모든 모델이 예측에 있어서 동일하게 영향을 준다고 가정하기 때문에 모델의 기여도에 따라 가중치를 부여하여 투표 앙상블보다 나은 성능을 기대
- 가중 평균 앙상블과 가중 합계 앙상블 모두 투표 앙상블의 확장형
- 투표 앙상블 경우, 모든 모델이 예측에 있어서 동일하게 영향을 준다고 가정하기 때문에 모델의 기여도에 따라 가중치를 부여하여 투표 앙상블보다 나은 성능을 기대

Ensemble Member Selection 소개
1) 정의: Ensemble Member Selection이란 앙상블 내 모델 조합을 최적화 시키는 알고리즘
2) 특징
• 앙상블의 성능 저하를 최소화하면서 앙상블 모델을 축소하고 이를 통해 앙상블 계산 복잡도를 감소시킴
• 단순히 voting과 stacking ensemble로 어떤 조합의 모델이 최고의 성능을 내는지 알 수 없기 때문에 Ensemble Member Selection 수행
3) 종류
• Ensemble Growing: 탐욕적 방법(Greedy manner)으로 더이상 성능 개선이 없을 때까지 앙상블에 모델 추가
• 탐욕적 방법(알고리즘): 현재 상황에서 가장 좋은 것을 고르는 알고리즘. 언제나 최적일 수는 없다는 특징을 가지고 있음
• Ensemble Pruning: 탐욕적 방법으로 더이상 성능 개선이 없을 때까지 전체 앙상블에서 모델을 제거 => 회귀분석에서의 stepwise feature selection(순차적 변수 선택)과 유사
4) 앙상블의 크기: 앙상블의 크기를 작게 하는 데에는 2가지 주요 원인이 존재한다.
1. Computational Overhead(계산적 오버헤드) 감소: 더 작은 크기의 앙상블은 더 적은 계산적 오버헤드를 발생 => Computational Overhead: 어떤 처리를 위해 들어가는 간접적인 시간
2. Accuracy(정확도) 향상: 앙상블의 일부모델들은 성능을 감소시키는 원인 모델 => 때로는 성능이 조금 저하되더라도 모델 복잡도를 크게 감소시키면 바람직하다고 간주
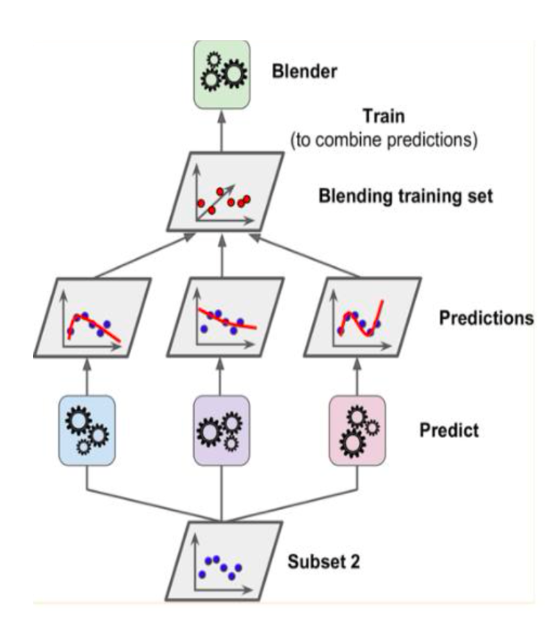
Stacking Ensemble 소개
1) 정의: 여러가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하여 예측하는 방법
2) 특징
• 성능 개선을 위해 개발되었지만, 언제나 성능 개선이 이루어지는 것은 아님
• 개별 모델들의 성능이 좋아야하며, 모델에서 나온 예측치 끼리 uncorrelated 되어야함
• 개별 모델(base model)의 수가 2개 이상이어야함
3) 스태킹에서 단계별 모델
• Base Models: 학습 데이터를 이용해 모델을 학습시키고 예측치들을 합침(Level 0)
• Meta Model: Base Models의 예측치를 합쳐 개선된 성능을 가진 모델 생성(Level 1)
4) Stacking = 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출하는 것 + 이를 기반으로 다시 예측
5) 여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해. 최종 메타 모델의 data set을 만드는 것이 중요
6) 이점: 분류/회귀 작업에서 성능이 좋은 다양한 모델의 기능을 활용 + 단일 모델보다 성능이 더 좋은 예측 가능
7) 목표: 스태킹 앙상블 성능 > 어떤 단일 기본 모델 성능: 그렇지 않다면 기본 모델을 앙상블 모델에 유리하게 사용
8) 스태킹의 구조
• 스태킹: 결합기가 개별 학습기를 결합하도록 훈련하는 일반적인 절차
- 개별 학습기 = 1단계 학습기
- 결합기 = 2단계 학습기 또는 메타 학습기
- 개별 학습기 = 1단계 학습기
- 결합기 = 2단계 학습기 또는 메타 학습기
• 스태킹 모델 구조 = Level 0 models(=기본 모델) + Level 1 model(= 메타모델)
- 기본 모델: 모델이 훈련 데이터에 적합 + 예측이 컴파일 됨
- 메타 모델: 기본 모델의 예측을 잘결합하는 방법을 학습
- 기본 모델: 모델이 훈련 데이터에 적합 + 예측이 컴파일 됨
- 메타 모델: 기본 모델의 예측을 잘결합하는 방법을 학습
반응형
'머신러닝' 카테고리의 다른 글
| [비지도학습] 클러스터링(k-means, GMM, DBSCAN)_차원축소(PCA, SVD)_개념, 정리 (2) | 2024.01.23 |
|---|---|
| [머신러닝] 앙상블(Ensemble) 기법_스태킹(Stacking)_알고리즘 소개(2) (1) | 2024.01.15 |
| [머신러닝] 앙상블(Ensemble) 기법_스태킹(Stacking)_개념 정리 (0) | 2024.01.15 |
| [머신러닝] 앙상블(Ensemble) 기법_부스팅(Boosting)_LightGBM (1) | 2024.01.13 |
| [머신러닝] 앙상블(Ensemble) 기법_부스팅(Boosting)_XGBoost (0) | 2024.01.13 |

