반응형
앙상블 기법 배깅 알고리즘 중 대표적으로 랜덤포레스트가 있습니다.
랜덤포레스트에 대해 소개해드리겠습니다.
Random Forest Algorithm
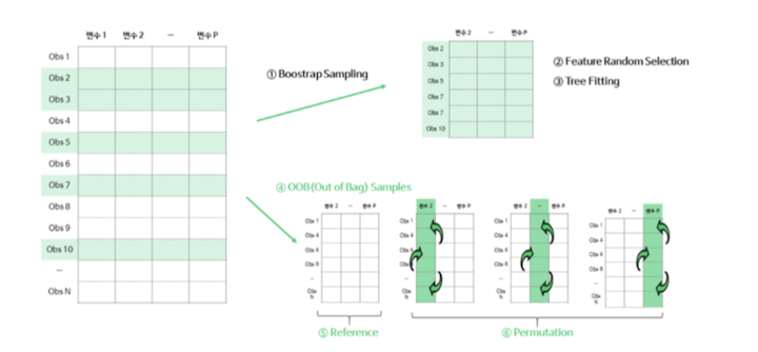
1) =Bagging, bootstrap sample을 이용해 각 decision tree(타알고리즘 x)를 학습 시킴
2) ≠ Bagging, 트리의 각 분기점에서 변수 선택을 함께 진행
3) 분기점의 기준이 될 후보 변수를 랜덤으로 선택한 뒤, 그 안에서 최적의 분할 기준을 선택(후보 중 일부 변수만 사용할 수 있음)
4) 각 분기점에서 사용될 수 있는 feature를 달리함으로써 diversity ↑
5) Random Forests의 tree들의 correlation을 제거함으로써 bagging을 보다 향상시킬 수 있을 거라는 아이디어를 바탕, 즉 correlation 제거하여 분산을 증가
6) 임의로 m개의 예측 변수를 고른 후 그 중에서 노드에 생성할 예측 변수를 선택, 일반적으로 m = √p
7) 랜덤 포레스트는 Bagging과 Random selection of feature가 결합된 방법
8) 배깅과 다른점: 설명 변수를 랜덤하게 선택한다는 점
9) 설명변수를 랜덤하게 선택함으로써 다양성을 확보, 모형간의 상관관계를 감소시킴, 개별 의사결정나무의 예측 결과 평균값이므로 분산을 감소하고 성능이 향상
Random Forest의 특징

1) 분산: B가 커지면 첫번째 항만 남고, 두번째 항은 사라짐, 상관계수가 작아지면 분산을 줄일 수 있음.
2) 장점: 높은 정확성, 해석용이성, 튜닝을 많이 하지 않아도 놀라운 성과를 나타냄
3) 회귀를 위한 랜덤 포레스트: 개별 트리로부터 예측한 값의 평균을 최종 예측값으로 설정, m=p/3, 최종 노드의 개수 =5
4) 분류를 위한 랜덤 포레스트: 개별 트리로부터 가장많이 선택된 class를 최종 예측(다수결), m = √p, 최종 노드의 개수 =1
Summary _ Bagging vs Random Subspace Ensemble vs Random Forest
•Bagging: bootstrap으로 각 트리에 사용될 데이터셋을 달리함(row 선택)
•Random Subspace Ensemble: 랜덤으로 변수를 선택해 각 트리에 사용될 데이터셋을 달리함(column 선택)
•Random Forest: bootstrap으로 각 트리에 사용될 데이터셋을 달리한 뒤, 하나의 트리안에서도 분기점마다 변수 선택으로 무작위성을 더함
Hyperparameters
•샘플크기(max_samples), Feature 개수(max_features), 트리 깊이(maz_depth), 트리 개수(n_estimators)
•Feature 개수: 분류의 경우, √((feature 총 개수))가 적절 | 회귀 경우, (feature 총 개수) / 3 가 적절 | max_feature = 1~7
• 트리 깊이: 깊이↑ => 과적합 정도 ↑ => correlation ↓ => 앙상블 성능 ↑, 1~10 levels가 효과적
반응형
'머신러닝' 카테고리의 다른 글
| [머신러닝] 앙상블(Ensemble) 기법_부스팅(Boosting)_GBM (1) | 2024.01.12 |
|---|---|
| [머신러닝] 앙상블(Ensemble) 기법_부스팅(Boosting)_Adaboost (1) | 2024.01.12 |
| [머신러닝] 앙상블(Ensemble) 기법_부스팅(Boosting)_개념 정리 (0) | 2024.01.12 |
| [머신러닝] 앙상블(Ensemble) 기법_배깅(Bagging)_개념 정리(2) (0) | 2024.01.12 |
| [머신러닝] 앙상블(Ensemble) 기법_배깅(Bagging)_개념 정리(1) (0) | 2024.01.12 |


